The number added (or subtracted) at each stage of an arithmetic sequence is called the "common difference" d, because if you subtract (find the difference of) successive terms, you'll always get this common value. The number multiplied (or divided) at each stage of a geometric sequence is called the "common ratio" r, because if you divide (find the ratio of) successive terms, you'll always get this common value.
- Find the common difference and the next term of the following sequence:
- 3, 11, 19, 27, 35,...
- 11 – 3 = 8
19 – 11 = 8
27 – 19 = 8
35 – 27 = 8
- Find the common ratio and the seventh term of the following sequence:
- 2/9, 2/3, 2, 6, 18,...
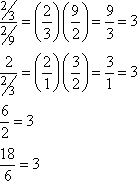
Since arithmetic and geometric sequences are so nice and regular, they have formulas.
For arithmetic sequences, the common difference is d, and the first term a1 is often referred to simply as "a". Since you get the next term by adding the common difference, the value of a2 is just a + d. The third term is a3 = (a + d) + d = a + 2d. The fourth term is a4 = (a + 2d) + d = a + 3d. Following this pattern, the n-th term an will have the form an = a + (n – 1)d.
For geometric sequences, the common ratio is r, and the first term a1 is often referred to simply as"a". Since you get the next term by multiplying by the common ratio, the value of a2 is just ar. The third term is a3 = r(ar) = ar2. The fourth term is a4 = r(ar2) = ar3. Following this pattern, the n-th term an will have the form an = ar(n – 1).
- Find the tenth term and the n-th term of the following sequence:
- 1/2, 1, 2, 4, 8,...
- an = (1/2) 2n–1
a10 = (1/2) 210–1 = (1/2) 29 = (1/2)(512) = 256
- Find the n-th term and the first three terms of the arithmetic sequence having a6 = 5 andd = 3/2. The n-th term of an arithmetic sequence is of the form an = a + (n – 1)d. In this case, that formula gives me a6 = a + (6 – 1)(3/2) = 5. Solving this formula for the value of the first term of the sequence, I get a = –5/2. Then:
- a1 = –5/2, a2 = –5/2 + 3/2 = –1, a3 = –1 + 3/2 = 1/2,
and an = –5/2 + (n – 1)(3/2)
- Find the n-th term and the first three terms of the arithmetic sequence having a4 = 93 anda8 = 65. Since a4 and a8 are four places apart, then I know from the definition of an arithmetic sequence that a8 = a4 + 4d. Using this, I can then solve for the common difference d:
- 65 = 93 + 4d
–28 = 4d
–7 = d
- 93 = a + 3(–7)
93 + 21 = a
114 = a
- a1 = 114, a2 = 114 – 7 = 107, a3 = 107 – 7 = 100
an = 114 + (n – 1)(–7)



 is the
is the